> ***原载于 GWmodel-Lab 公众号*** 📎题目:*Uncovering Spatial Heterogeneity in Real Estate Prices via Combined Hierarchical Linear Model and Geographically Weighted Regression* 📖期刊:Environment & Planning B 空间异质性对于探索房地产价格与其影响因素之间的数据关系具有重要意义,地理加权回归(GWR)是实现这一目的常用技术。在这项研究中,我们收集了武汉市二手房价格数据,在这套数据中,同一个小区内的二手房具有相同的坐标。因此,该数据存在一个典型特点:数十个甚至几百个样本具有相同的坐标,但是又有不同的属性。这个特性可能会在带宽优选和回归系数估计时导致严重的问题。我们通过将GWR模型与分层线性模型(Hierarchical Linear Model, HLM)进行结合,提出了一个名为HLM-GWR的扩展模型,以处理这些问题。结果显示,HLM-GWR在带宽优选、回归系数估计方面与传统GWR和HLM模型相比具有明显改善。借助模拟数据,我们也验证了HLM-GWR的这项优势。总体而言,HLM-GWR模型是可用的,而且在样本具有这类空间分布模式的情形下,更推荐使用该模型。 # 什么是HLM-GWR模型 正如我们在摘要中所说的,分层线性与地理加权复合模型(HLM-GWR)是将 GWR 模型与 HLM 模型相结合得到的一个新模型。相信经常关注我们公众号的朋友们对 GWR 比较熟悉了,那么 HLM 是什么模型呢? > **维基百科**: > > 分层线性模型(也称为多层模型、线性混合效应模型、混合模型、嵌套数据模型、随机系数、随机效应模型、随机参数模型或分图设计)是参数在多个级别上变化的统计模型。HLM 特别适合于研究样本数据组织具有多个级别(即嵌套数据)的情形。HLM 可用于具有多个级别的数据,最常见的是具有两个层级的模型。 通过对数据按照一定方法分组,构建 HLM 模型,将自变量引起的因变量的变化分为组内和组间两部分,可以更好地分析数据中“组内同质、组间异质”的特点。 那么,如果数据是空间数据,分组的依据是样本的空间位置呢?  对于一些变量,尤其是和空间具有强相关性甚至由位置直接决定的变量,例如到最近水系的距离、最近商圈的距离等,同一个位置上的样本共享这些变量,这就是“组级变量”。此外,同一组内的各个样本还有一些“样本级变量”,例如是否是精装修、是否是高楼层等。这样就构成了一个“分层线性模型”。 除此之外,我们还知道,对于空间统计学的研究对象,空间异质性和相关性是广泛存在的。因此,水系、商圈等对房价的影响也是有空间异质性,但同时根据地理学第一定律,相近水系、商圈等对距离相近的二手房房价的影响相似。因此,如果我们在求解“组级变量”对应的回归系数值时,使用地理加权回归技术,就可以实现对于组级变量的空间异质性分析。  在这个模型中,我们称只由样本级变量组成的部分为“一层模型”,只由组级变量组成的部分为“二层模型”。二层模型就是使用地理加权回归模型求解的部分。 # 为什么要使用HLM-GWR模型 ## 对这类数据,GWR模型会存在什么问题? 当使用GWR分析这类数据时,由于同一个位置上可能有数量不同的样本,在优选带宽时,可变带宽的实际“尺度”并不一样,有的地方大,有的地方小。下图中圆圈代表了某些点位上可变带宽对应的实际带宽范围,可见有的地方带宽非常小,造成了很强的局部性。 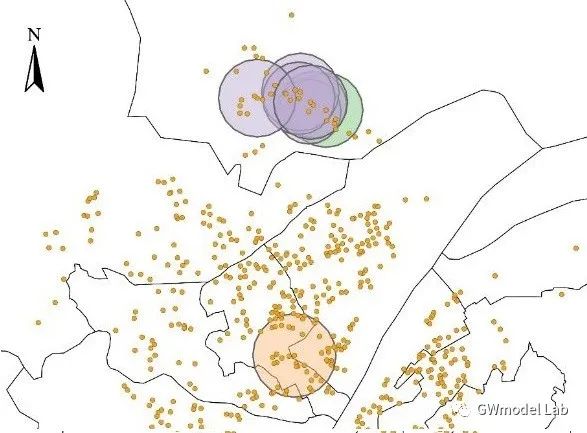 ## 如果使用固定带宽保证空间尺度统一呢? 事实上,如果使用固定带宽,局部极值导致黄金分割算法容易陷入局部最优解,而且也容易导致CV值无穷大,从而无法选出固定带宽。 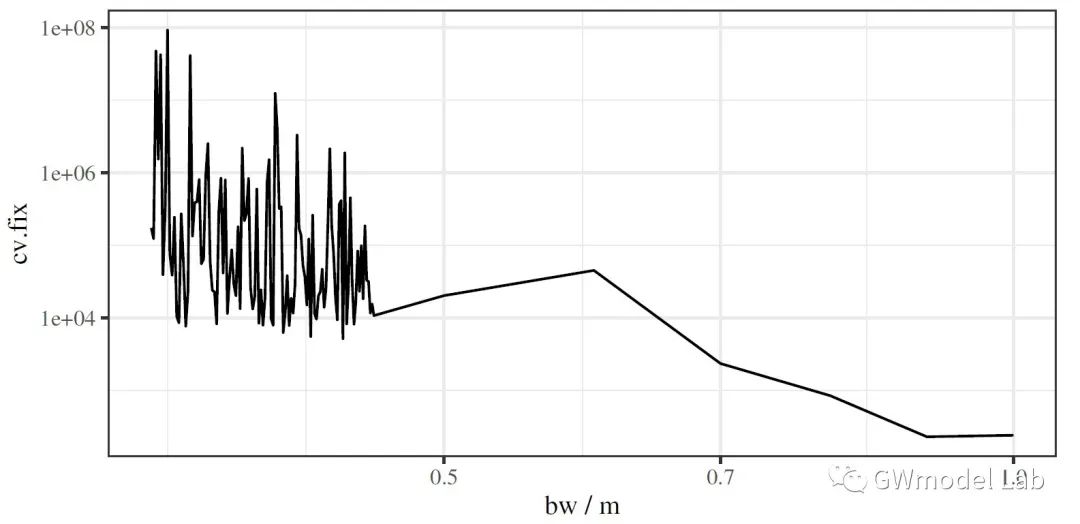 > GWR模型、高斯核函数 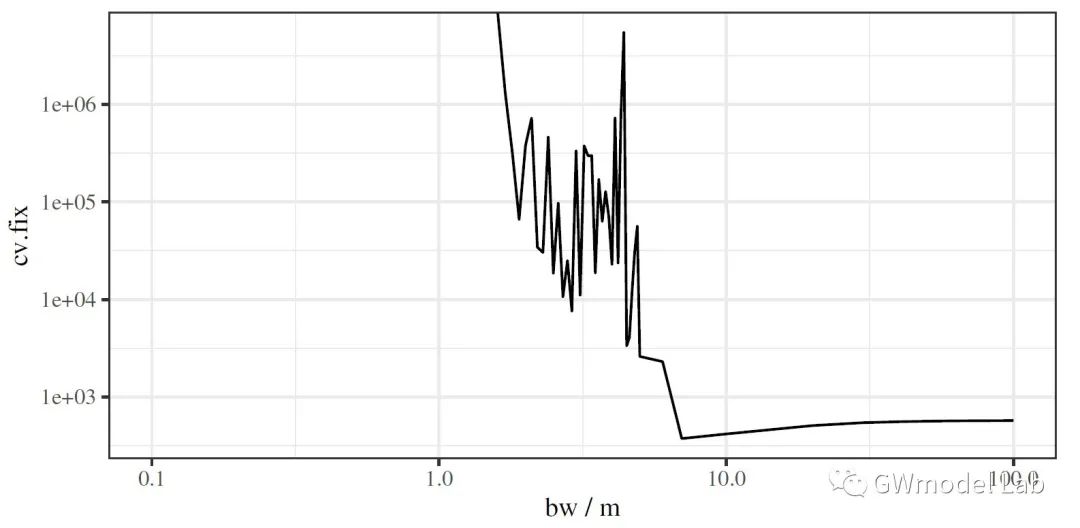 > GWR模型、Bi-square函数 ## HLM-GWR模型对系数估计效果有提升吗? 在一个模拟数据实验中,我们分别随机生成了三组回归系数 $g_1$,$h_1$,$h_2$。系数$g_1$服从明显的空间分布模式,系数$h_1$在空间中随机分布,系数$h_2$在空间中保持常值,截距也具有一定的空间分布。 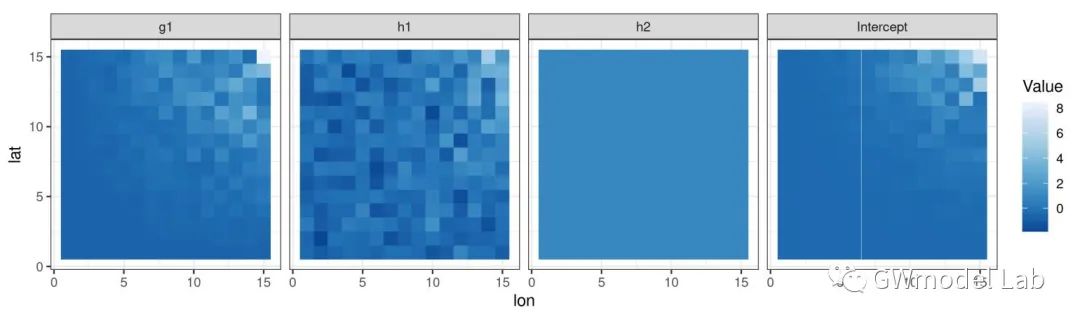 在分别使用GWR模型、HLM模型、HLM-GWR模型进行拟合后,将估计的回归系数值和真实值进行对比,发现HLM-GWR的估计效果更好。对于$g_1$和$h_1$而言,HLM-GWR的估计更接近真实值。 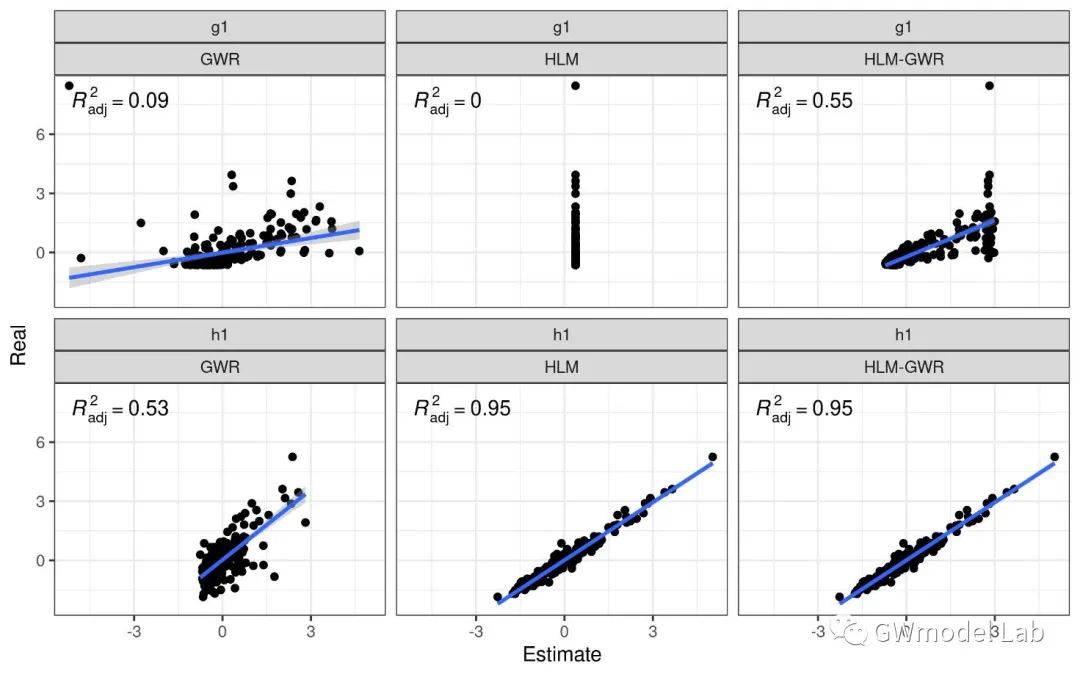 总体上,HLM-GWR能够对三个回归系数都产生比较好的估计值,但是GWR模型的估计偏差比较大,而HLM模型对于组级变量的回归系数($g_1$)无法体现出空间异质性。 # 如何使用 HLM-GWR 模型 下面小R就以文章中的数据为例,展示一下如何使用 HLM-GWR 模型。我们所使用到的数据主要有二手房数据、兴趣点数据(POI)和兴趣区数据(AOI)数据。对于POI和AOI数据,计算每个二手房样本到各类POI或AOI中最近一个的距离。最终得到了很多的变量。 ## 数据 二手房数据: 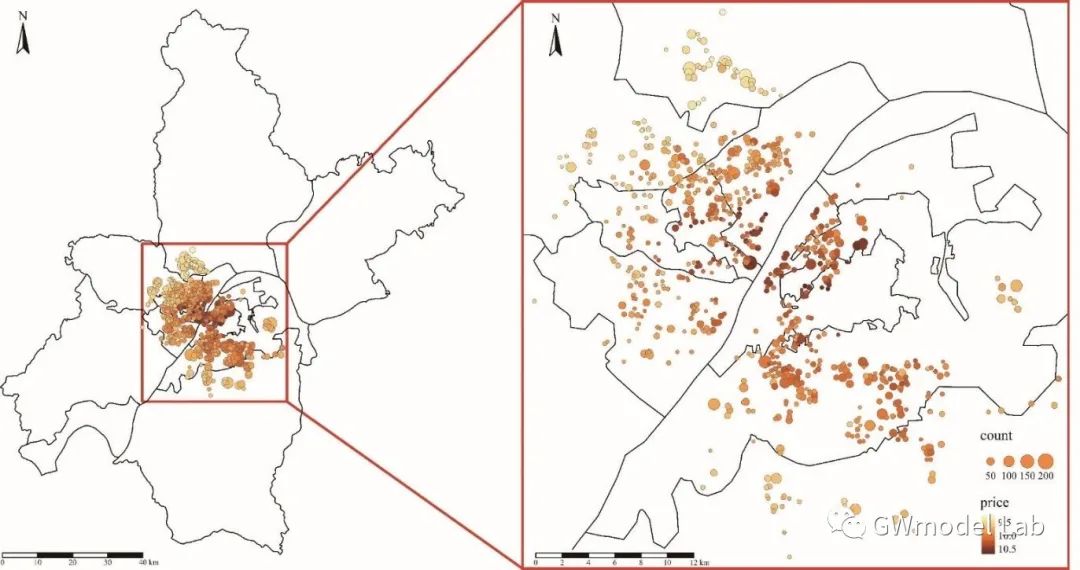 POI和AOI数据: 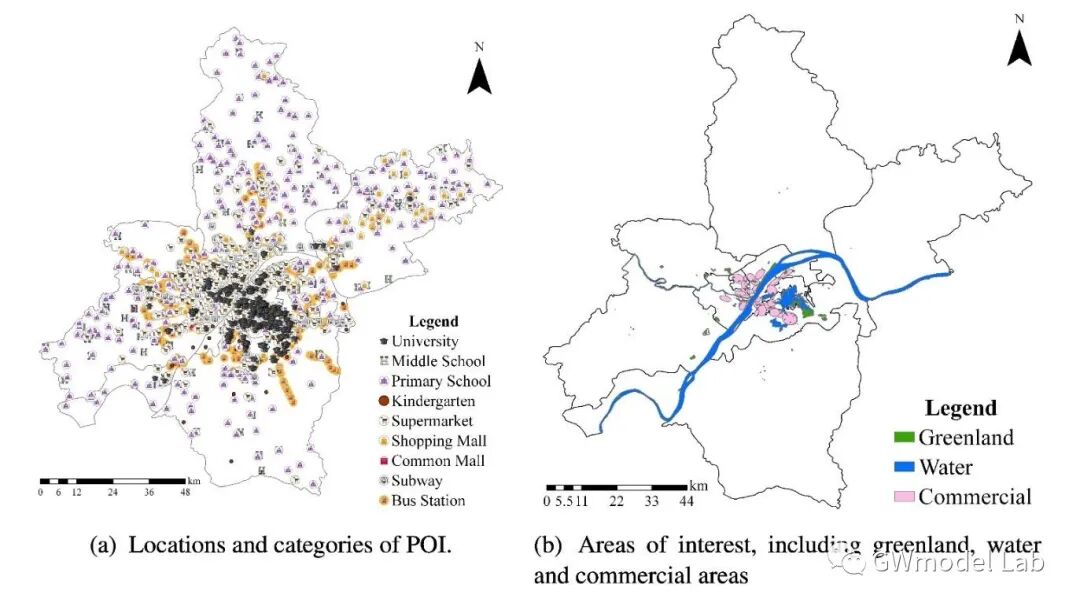 ## 使用 HLM-GWR 进行分析的流程 1. 模型优选。分别借助GWR模型和HLM模型的变量优选方法选择最优变量组合,剔除无关变量,最后根据研究目的将两种变量优选方法选出来的变量进行综合考虑,确定最终的模型。 2. HLM求解过程。保留所有样本级变量,将组级变量和截距放在一起,当作HLM模型求解过程的“组合截距”。使用HLM模型的解法,求解样本集变量的回归系数,以及“组合截距”。 3. GWR求解过程。将HLM求解过程的“组合截距”值当作GWR求解过程的因变量,将组级变量当作自变量,根据组的位置求解一个GWR模型,得到组级变量的回归系数。 之后将 HLM 求解过程和 GWR 求解过程得到的回归系数放在一起,就是 HLM-GWR 模型的结果。这一方法被称为“两步法”。当前,两步法并不是最终的解决方案,这一点在日后我们会进行改进。在该实验中,得到的回归系数估计值使用地图进行展示。 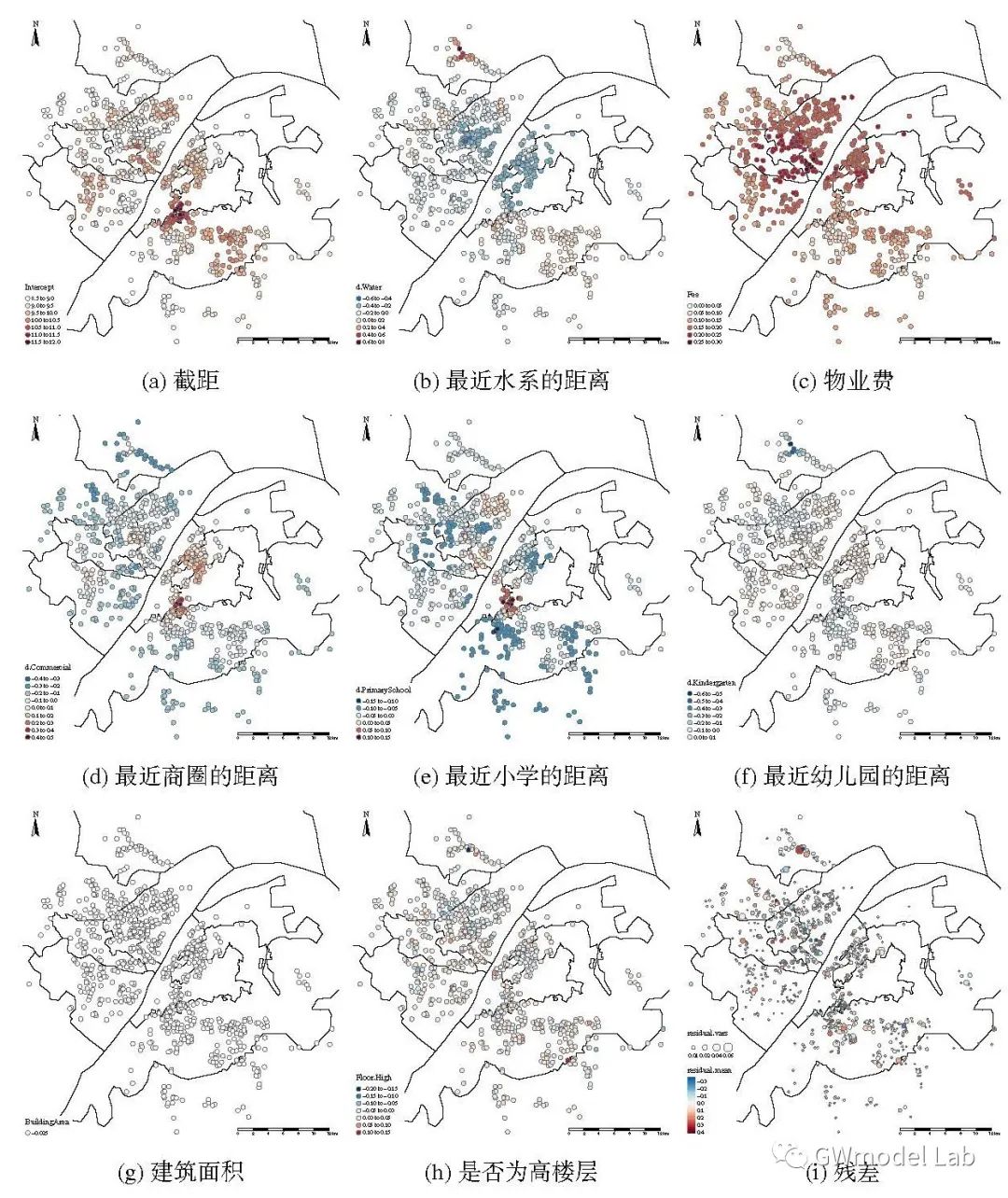 这样得到回归系数估计值,即可以保持“组间异质性”,又可以充分考虑“组内同质性”。 --- 其实从那个模拟实验我们就可以看到,如果在一个位置有足够多的样本,HLM模型就已经可以取得不错的效果。但是如果是空间相关性很强的变量,或者由位置直接决定的变量,同一个位置上所有样本的变量值都相同,这个时候就无法进行回归了,只能借助地理加权回归方法进行回归。那这么看来,HLM-GWR是否更能反映地理背景对事件影响的本质呢?