*原载于 GWmodel Lab 微信公众号*
> **摘要**
>
> 地理加权回归(GWR)技术是一项久经使用的空间分析工具,已经被应用到许多领域。但是在处理大型数据集的时候在性能上仍然面临巨大的挑战,而这种情况随着技术的发展会越来越普遍。在这项研究中,我们提出了两种GWR在R语言中的高性能实现,一种实现基于多核并行(MP),另一种基于CUDA。这两种实现分别被成为GWR-MP和GWR-CUDA。我们将这两种实现与其他已有的实现(即GWmodel包的现有实现、MGWR和FastGWR)进行了比较,发现这些实现在不同数据量的情况下表现不同,因此并没有哪种实现总是性能最好。具体地,GWmodel包的实现和MGWR在小数据量的情况下具有可接受的性能。对于大数据集,GWR-MP和FastGWR虽然都是基于常规多核并行的实现,但GWR-MP在每个核或线程上的性能要高于FastGWR。只有当数据量非常大时,GWR-CUDA实现的性能最高,数据量较小时其I/O成本过高导致性能并不突出。综上,GWR-MP和GWR-CUDA都可以作为现有GWR实现在R语言中的高性能版本,且在数据量不同时性能可以互补。对于大数据量的GWR研究,这两种实现应该是首选。
>
> [查看原文](https://www.tandfonline.com/doi/full/10.1080/10095020.2022.2064244)
相信通过摘要大家已经对GWR-MP和GWR-CUDA已经有了初步的认识,下面先通过一幅图给大家进行直观地展示各种GWR实现的性能对比情况。
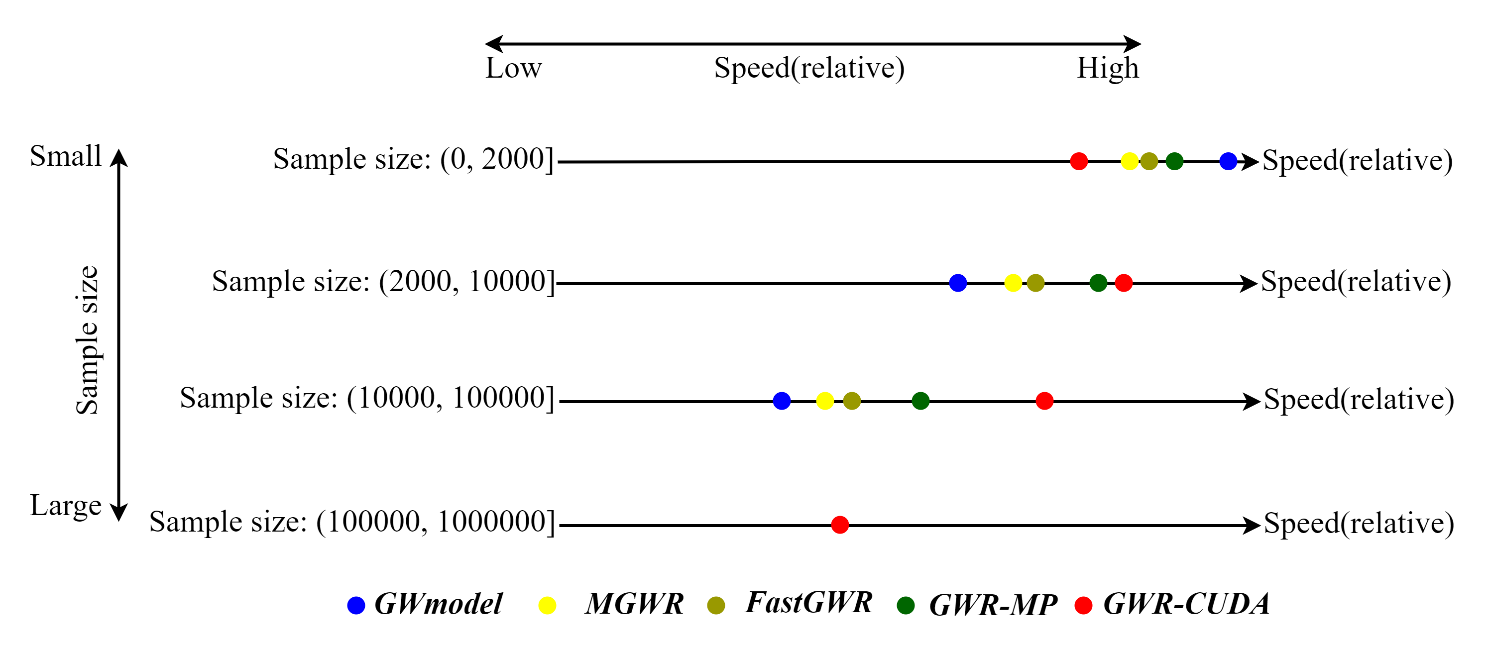
下面我们就为大家详细介绍文章的主要内容。
# 为什么要做高性能实现
有很多文章分析了GWR算法的时间和空间复杂度都是 $O(n^2)$。而分析算法性能主要就是从这两个方面进行。下面我们就分别从空间复杂度和时间复杂度分别分析,为什么GWR算法的性能需要改进?到底是什么因素制约了GWR算法的性能。
## 空间复杂度
空间复杂度主要是由于空间距离矩阵、权重矩阵的大小是 $n×n$,以及检验用的帽子矩阵大小也是 $n×n$,所以需要消耗大量的内存来存储这些矩阵。我们可以简单计算以下,如果是 10 万个样本,用64位的双精度浮点数计算,需要多少内存来存储空间距离矩阵呢?
$$
{100000}^2 \times 64 / 8 / {1024}^3 = 74.50581 \; \mathrm{(GB)}
$$
足足需要 74 GB 的内存才能存储下来!也许高性能服务器能满足这个要求,但这对于个人电脑而言,可能就无法分配内存了。即便使用虚拟内存,也不能满足需求,况且性能会降低非常严重。这还只是10万的数据量。如果是栅格数据,样本量就更大了。所以这是制约GWR在大数据中应用的一个重要限制。
## 时间复杂度
再来看时间复杂度。由于不同计算机的硬件条件不同,算法执行的速度也有快慢,我们无法给出一个时间的准确值。但是在我们实验室的服务器上,10万样本的数据,GWmodel包的常规实现需要运行4000多秒,也就是1个多小时。那如果数据量继续增加到100万,甚至1000万,可能算法需要运行一两年了。这就使得GWR在大数据中的可用性大大降低。
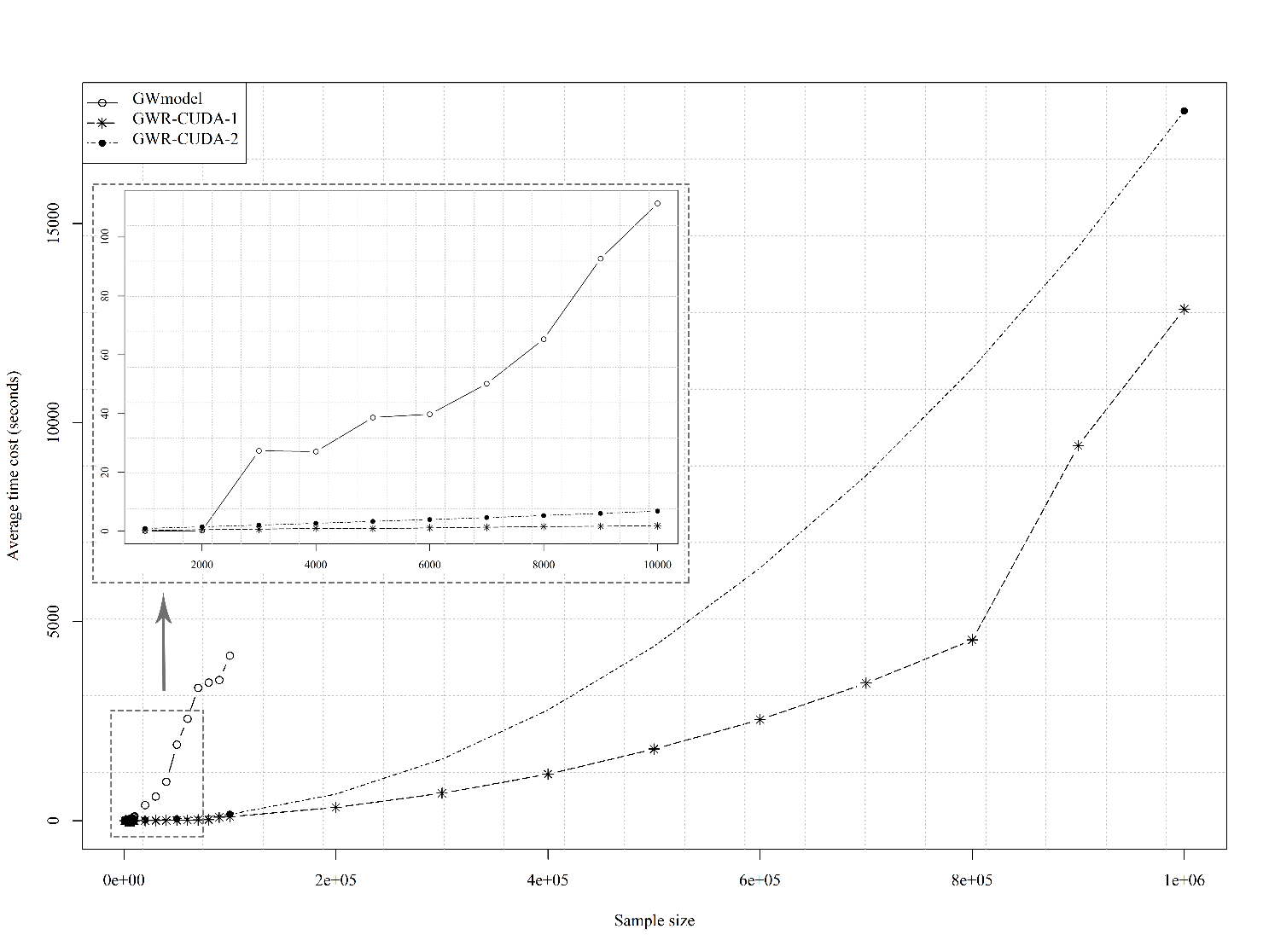
# 如何实现高性能算法
从上面的分析我们已经可以看到,如果要解决空间复杂度的问题,就需要避免在计算中使用 n×n 的矩阵。如果要解决时间复杂度的问题,就需要使用并行计算技术,使用更强大的算力以加快计算的进程。同时,选择一个高性能的编程语言非常重要,也可以大大提高性能。所以我们就选择了C和C++进行实现。
## 内存使用的优化
我们先来分析一下到底GWR在计算中使用了那些 $n×n$ 的矩阵:权重矩阵 $W$、距离矩阵 $D$、帽子矩阵 $S$。那么这些矩阵是否每一个元素都必须存储且用到呢?不是!
* 权重矩阵 $W$ 只有对角线元素会用到,而且非对角线元素是0。
* 距离矩阵 $D$ 可以根据样本坐标进行计算,无需存储。
* 帽子矩阵 $S$ 只会用到其迹,以及 $SS^\mathrm{T}$ 的迹。
这样我们就对这几个矩阵分别处理,将矩阵计算进行拆解,单独把需要用到的元素计算出来,内存使用的问题就迎刃而解了。具体如何计算还请读者参考论文中的相关推导。
## 多线程并行的实现
犹记得在上高性能地理计算的课程时,老师说过:“做高性能地理计算见到 for 循环就像见到宝贝一样。”熟悉GWR算法的读者应该很了解,GWR是一个逐点算法,在每个样本上都要计算一次,而且每个样本之间的计算互不干扰。实际上就是一个 for 循环实现的。那么想要做多线程并行就简单多了,使用 OpenMP 将 for 循环并行化即可。
1. **使用C++实现完整解算过程**。计算当前样本到其他样本的距离、计算距离对应的权重、最小二乘解算、计算当前样本在 $tr(S)$ 和 $tr(SS^\mathrm{T})$中的元素。
2. **使用OpenMP并行化**。每个线程单独执行一个完整的解算过程,计算完成后对每个线程计算的结果进行汇总,得到回归系数以及帽子矩阵的迹等数据。
3. **其他过程的并行化**。对于F检验过程,无法在上述并行化解算过程中得到所有需要的数据。需要进一步对该部分进行并行化处理。
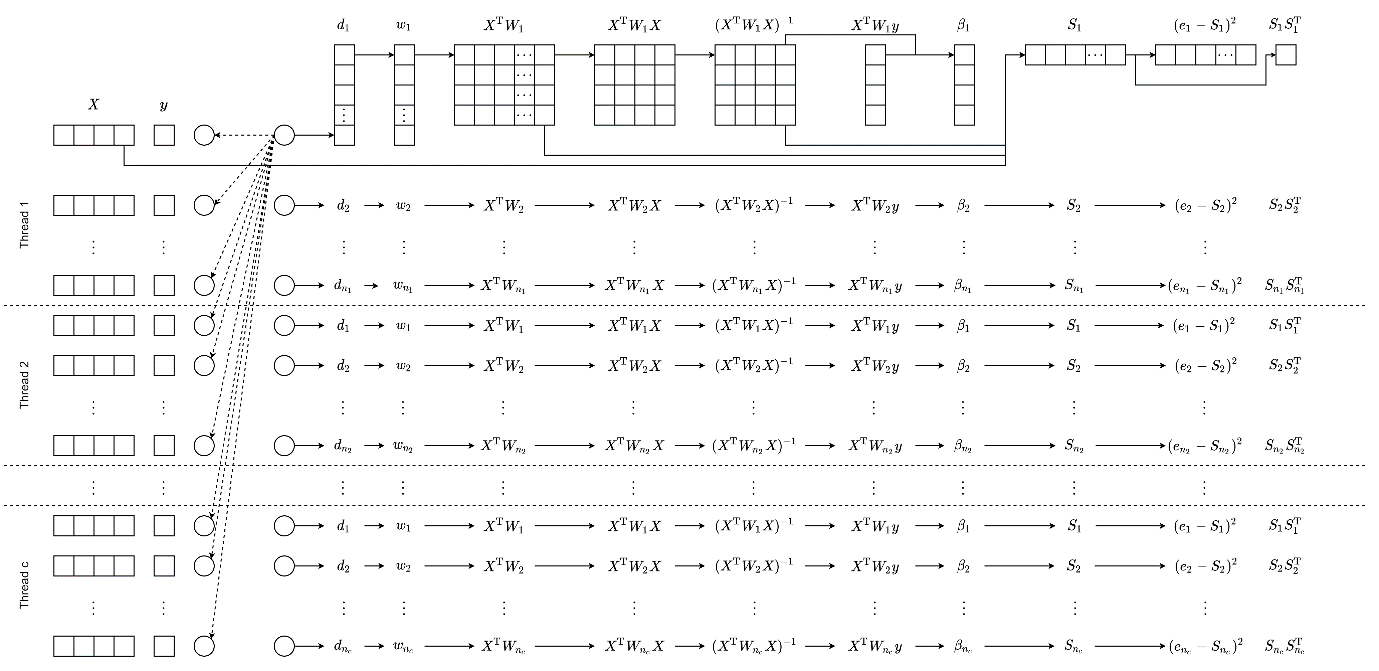
按照以上实现过程实现的GWR算法,就是前文中提到的GWR-MP。事实证明在大多数情况下,使用GWR-MP几乎可以榨干CPU的全部性能,让GWR结果立等可取,即使是在选带宽的时候,也不需要 "Take a cup of tea and have a break" 了。
## GPU加速的实现
在多线程实现的时候,我们提到每个线程单独执行一个完整的解算过程。但是常用的CPU也就同时执行几个或十几个线程,服务器级别的CPU可能也就几十或一百多线程。如果数据量更大,这些线程似乎就有点杯水车薪了。但是,一个消费级GPU可能有几千个流处理器,而且在解算矩阵的时候与CPU相比有很大性能上的优势。但是CUDA所支持的操作比较有限,肯定是不能把完整的解算过程放到流处理器中完成的。那该怎么去实现呢?
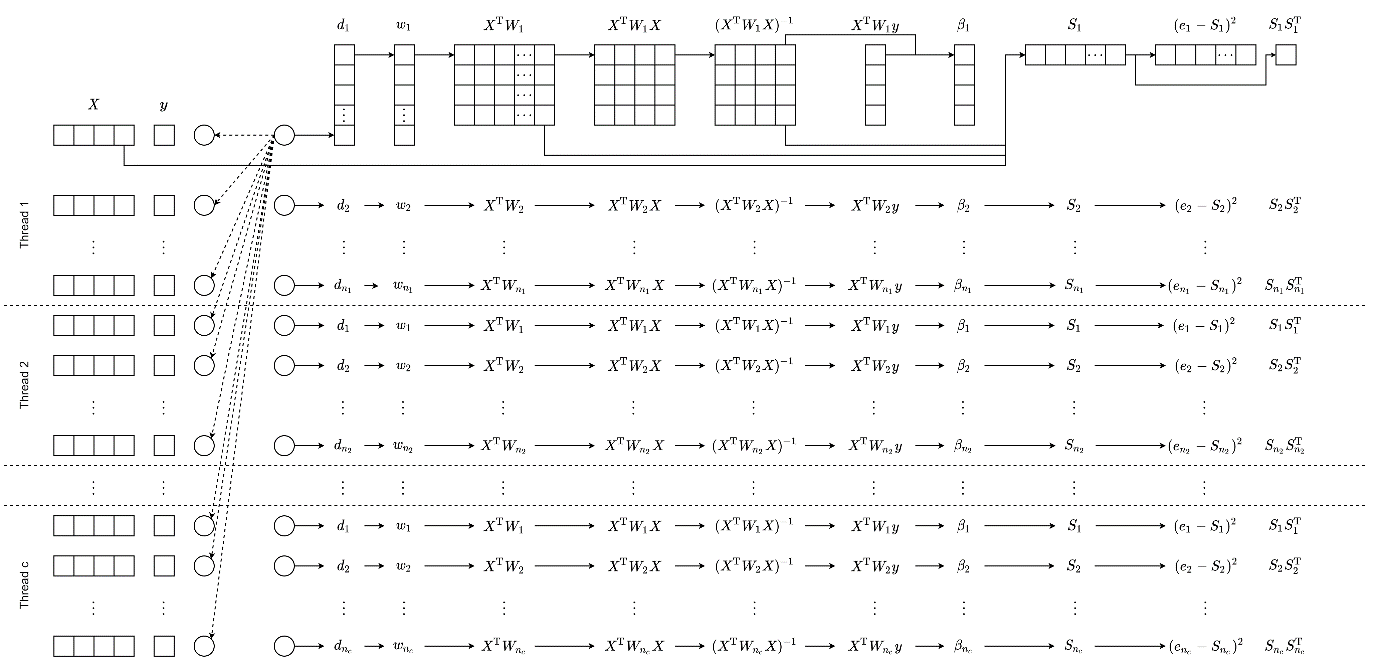
通过对算法执行过程每一步的分析我们发现,最小二乘求解的部分,尤其是其中求逆的部分需要花费大量的时间,事实上这一步也是模型解算的核心。可以说,求了逆就相当于完成了完整解算过程中最重要的部分。恰好,CUDA中有一个同时求多个矩阵的逆矩阵的接口,那就是我们要找的东西了!由此我们实现了GWR-CUDA算法。
下面的动图就是实现方式的示意。总的来说,就是把数据分组,每次循环计算一组数据,这一组数据中的求逆过程使用CUDA的并行求逆接口进行求解,然后批量求这些矩阵的诊断信息。
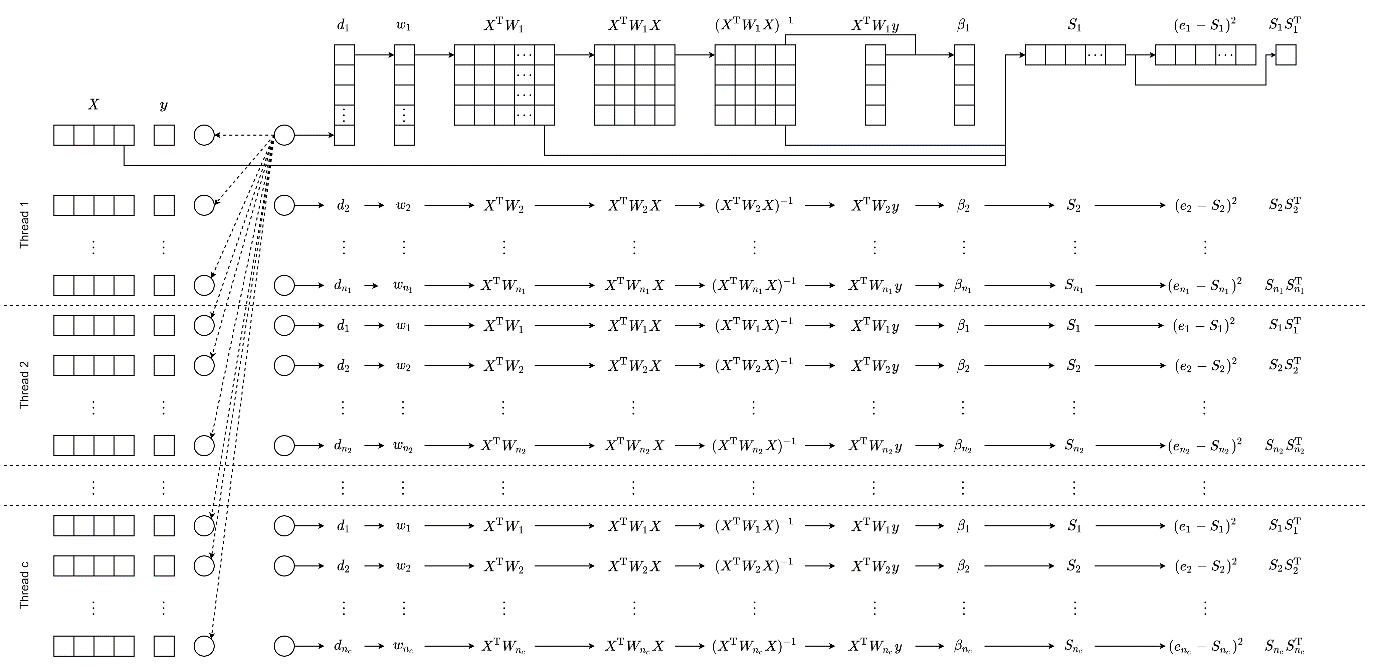
下面是更完整的算法流程。
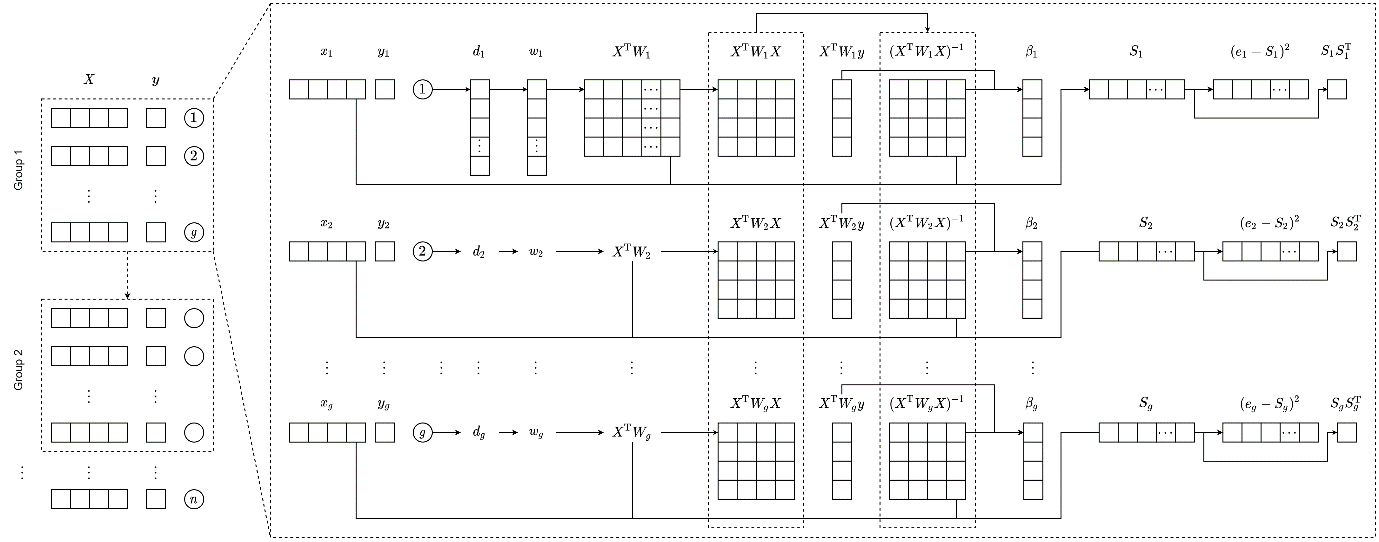
这中间还有很多细节,比如在Windows上R语言的包是MinGW编译的,CUDA却只能用MSVC编译,如何将二者结合起来。以及如何在Linux上让R在配置包编译参数的时候找到CUDA相关的库。这里就先不展开了。
# 高性能算法表现如何
经过大量反复地实验,我们所实现的GWR-MP和GWR-CUDA算法不负众望,取得了非常好的加速效果。以至于笔者本人在实验的时候已经离不开并行实现了。下面是我们实验用的机器。
| 项目 | 参数 |
| ------ | ---------------------- |
| 机型 | ThinkSystem SR650 |
| CPU | Intel Xeon Gold 5118 |
| GPU | NVIDIA Tesla V100 |
| 内存 | 128 GB |
| 系统 | Ubuntu 20.04 |
其他的话就不多说了,直接上对比图(第一组图是运算时间的对比,第二组图是加速比的对比)。
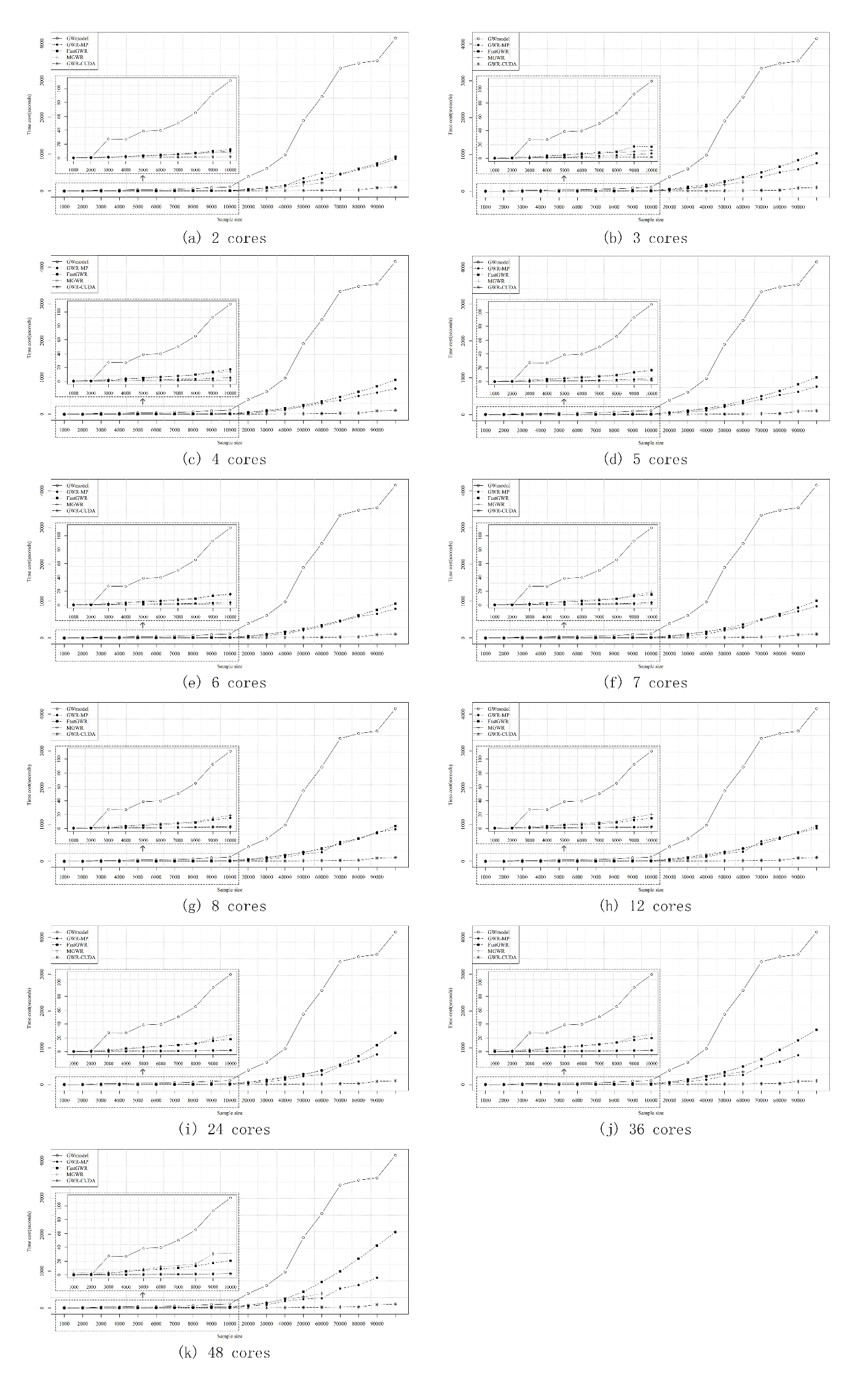
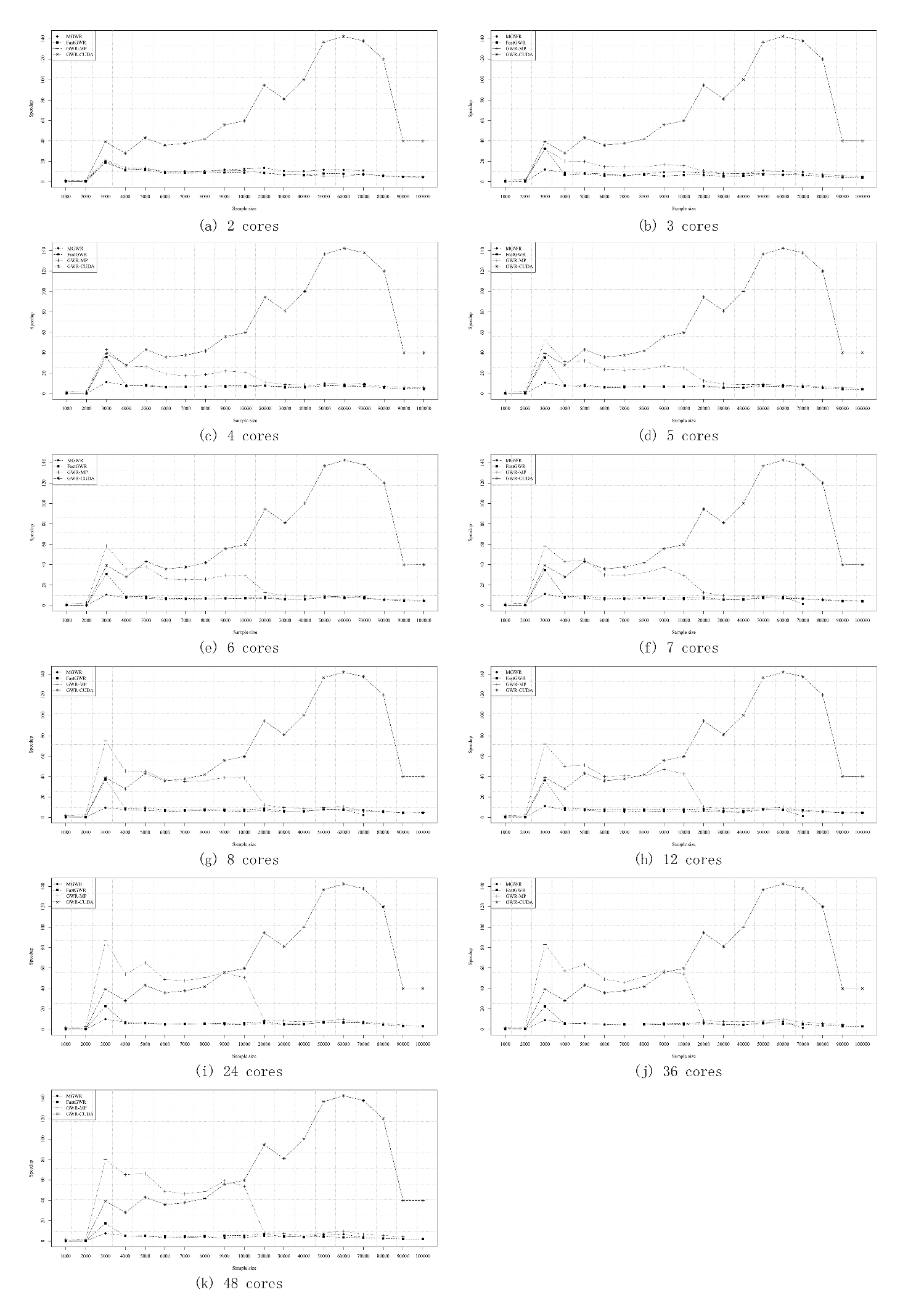
总的来说,当样本量小于1万时,用什么算法其实差距不是很明显,除了GWR-CUDA的性能会略微下降。当样本量在1万到10万之间时,GWR-MP的性能提升是最明显的。但当样本量进一步增加时,GWR-CUDA则是更好的选择。
# 怎样使用高性能算法
目前GWR-MP和GWR-CUDA的代码已经添加到GWmodel包中了,只是GWR-CUDA实现需要自行编译才能使用,而GWR-MP可以从CRAN安装。
## 使用GWR-MP
GWR-MP的使用可以通过下面代码所示的方式进行调用。其中,参数 `parallel.arg` 是用于指定创建多少个线程进行并行,一般不要超过CPU最大支持的线程数。
```R
bw.CV.omp <- bw.gwr(formula = PURCHASE ~ FLOORSE + BATH2 + UNEMPLOY,
data = londonhp,
approach="CV",
kernel = "gaussian",
adaptive = adaptive,
parallel.method = "omp",
parallel.arg = 8)
gwr.basic(formula = PURCHASE ~ FLOORSE + BATH2 + UNEMPLOY,
data = londonhp,
kernel = "gaussian",
adaptive = T,
parallel.method = "omp",
parallel.arg = 8)
```
## 使用GWR-CUDA
若要在Windows上使用GWR-CUDA,可以下载GWmodel的源码,安装CUDA套件之后,确保环境变量中有`CUDA_PATH`,然后使用下面命令编译安装。
```powershell
R.exe CMD INSTALL GWmodel
```
若要在Linux上使用GWR-CUDA,可以在 R 中使用如下命令安装,但是注意要提前设置好 `CUDA_HOME` 的环境变量。
```R
install.packages("GWmodel", configure.args = "--enable-cuda=yes")
```
成功安装后,GWR-CUDA和GWR-MP的使用方法类似,只是将 `parallel.method` 的值换成 `"cuda"`。参数 `parallel.arg`是用于指定一次求解的样本量,这个数值并不影响性能,但是需要根据显卡显存大小进行设置。一般情况下,设置`parallel.arg` 为 64 即可。
---
以上就是对高性能地理加权算法的全部介绍了,希望高性能算法能够帮助大家节省更多时间,减少等待的焦躁。如果有什么问题可以关注公众号并留言哦!
> **题目**
>
> High-performance Solutions of Geographically Weighted Regression in R
>
> **作者**
>
> Binbin Lu, Yigong Hu, Daisuke Murakami, Chris Brunsdon, Alexis Comber, Martin Charlton, Paul Harris
>
> **期刊**
>
> Geo-spatial Information Science
>
> **DOI**
>
> [10.1080/10095020.2022.2064244](https://www.tandfonline.com/doi/full/10.1080/10095020.2022.2064244)
>